pd.to_numeric()
- 숫자 문자열을 숫자로 변환합니다.
- pd.to_numeric(데이터, 오류=”1/2/3″)
- 오류에는 세 가지 옵션이 있습니다.
- 1. ‘Error = Ignore’ : 숫자로 변환할 수 없는 데이터는 원래 데이터로 돌려준다.
- 2. ‘errors=coerce’: 숫자로 변경할 수 없는 데이터는 nan으로 반환됩니다.
- 3. ‘errors = raise’: 숫자로 변경할 수 없는 데이터가 있으면 오류를 발생시키고 코드를 중지합니다.
교육 및 예측 데이터 세트 분할
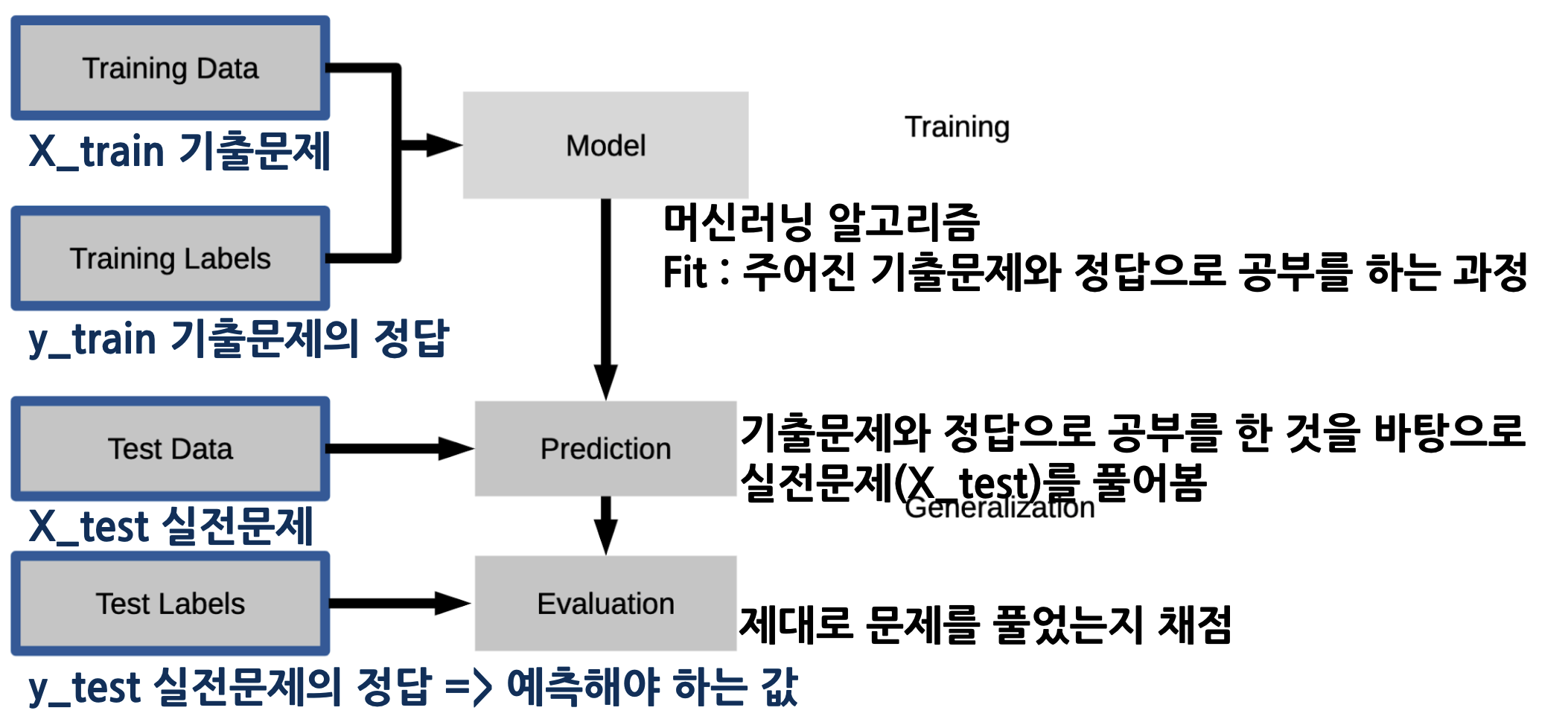
- X_train: 학습(훈련)을 위한 데이터 세트
- X_test : 예측에 사용할 데이터 세트
- y_train : 학습(훈련)을 위한 정답값
- y_test : 정확한 예측 값
1. 문제(특징)와 답변(라벨)을 나눕니다.
– X(특징), y(태그)
2. 교육 및 예측 데이터 세트 생성
-x_move, y_move, x_test, y_test
– 전체 데이터 중 학습과 예측의 비율을 결정하여 배포한다.
# 일반적으로 전체 데이터 중 80%를 학습( train )으로, 20%를 검증( test )으로 사용합니다.
# train 과 test 로 나누기 위해 데이터의 80%을 나눌 기준 인덱스 구합니다.
split_count = int(df.shape(0)*0.8)
# 데이터의 80%을 나눌 기준 인덱스(split_count)로 문제 데이터(X)를 train, test로 나눕니다.
X_train = X(:split_count)
X_test = X(split_count:)
# 데이터의 80%을 나눌 기준 인덱스(split_count)로 정답 데이터(y)를 train, test로 나눕니다.)
y_train = y(:split_count)
y_test = y(split_count:)
기계 학습 알고리즘 가져오기: sklearn / DecisionTreeClassifier
- 기계 학습 모델의 성능을 개선하는 방법
- 데이터 세분화
- 데이터 전처리, 결측치 처리
- 기능 선택, 기능 엔지니어링(스케일링, 변환, 코딩)
- 모델의 매개변수 값을 변경하는 방법
# 사이킷런(sklearn)에서 의사 결정 트리 분류모델(DecisionTreeClassifier)을 로드합니다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(criterion='entropy', random_state=42)
# 데이터를 머신러닝 모델로 학습(fit)합니다.
# 기출문제 X_train과 기출문제의 정답 y_train을 넣고 학습을 합니다.
model.fit(X_train, y_train)
# 데이터를 머신러닝 모델로 예측(predict)합니다.
y_predict = model.predict(X_test)
평가: 정확도
# 정확도(accuracy)
(y_test == y_predict).mean()
# 정답과 같이 예측한 값은 True 로 나오게 됩니다.
# True == 1 이기 때문에 평균값을 내면 정답을 맞춘 비율을 구할 수 있습니다.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
# 정답을 알고 있을 때만 사용할 수 있습니다.
model.score(X_test, y_test)
트리 알고리즘 분석: Gini 오염
※ 지니공해란?
- 지니 불순도는 집합이 얼마나 이질적인지 측정한 값이며 CART 알고리즘에서 사용됩니다.
- 집합에서 요소를 선택하여 레이블을 무작위로 추측할 때 틀릴 확률입니다.
- 집합의 모든 요소가 같을 때 지니 불순도의 최소값은 0이며 집합은 완전히 순수하다고 말할 수 있습니다.
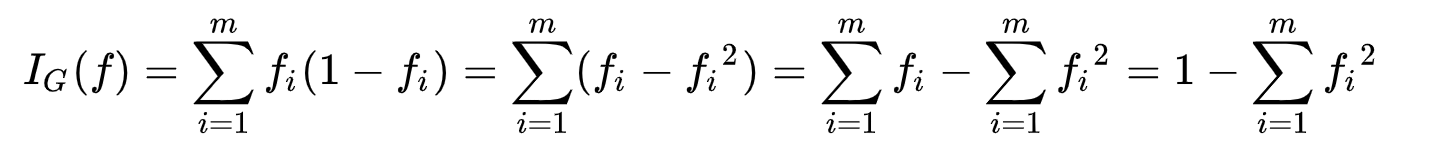
# 아무것도 섞여있지 않을 때 지니불순도
1-(1/1) **2
# 두 가지 클래스를 분류할 때 반반이라면, y축 값이 가장 높은 값이 0.5가 됩니다.
# 최악 상황의 지니불순도
1-(5/10) **2 -(5/10)**2
# 루트노드의 지니불순도 구하기
# 지니불순도가 0에 가까울수록 좋음.
1-(4137/5625)**2 - (1488/5625)**2
# entropy
# 앞에 - 를 붙여주는데 1보다 작은 값에 로그를 적용해 주기 때문에 결과가 음수가 나올 수 밖에 없기 때문에
# 앞에 - 를 붙여서 양수로 만들어 줍니다.
-(((4137/5625)*np.log2(4137/5625)) + ((1488/5625)*np.log2(1488/5625)))?
기계 학습의 맛.